Просто о WebRTC

Большинство материала по WebRTC сосредоточено на прикладном уровне написания кода и не способствует пониманию технологии. Попробуем углубиться и узнать как происходит соединение, что такое дескриптор сессии и кандидаты, для чего нужны STUN и TURN сервера.
WebRTC
Введение
WebRTC – технология, ориентированная на браузеры, которая позволяет соединить два клиента для видео-передачи данных. Основные особенности – внутренняя поддержка браузерами (не нужны сторонние внедряемые технологии типа adobe flash) и способность соединять клиентов без использования дополнительных серверов – соединение peer-to-peer (далее, p2p).
Установить соединение p2p – довольно трудная задача, так как компьютеры не всегда обладают публичными IP адресами, то есть адресами в интернете. Из-за небольшого количества IPv4 адресов (и для целей безопасности) был разработан механизм NAT, который позволяет создавать приватные сети, например, для домашнего использования. Многие домашние роутеры сейчас поддерживают NAT и благодаря этому все домашние устройства имеют выход в интернет, хотя провайдеры интернета обычно предоставляют один IP адрес. Публичные IP адреса - уникальны в интернете, а приватные нет. Поэтому соединиться p2p - трудно.
Для того, чтобы понять это лучше, рассмотрим три ситуации: оба узла находятся в одной сети (Рисунок 1), оба узла находятся в разных сетях (один в приватной, другой в публичной) (Рисунок 2) и оба узла находятся в разных приватных сетях с одинаковыми IP адресами (Рисунок 3).
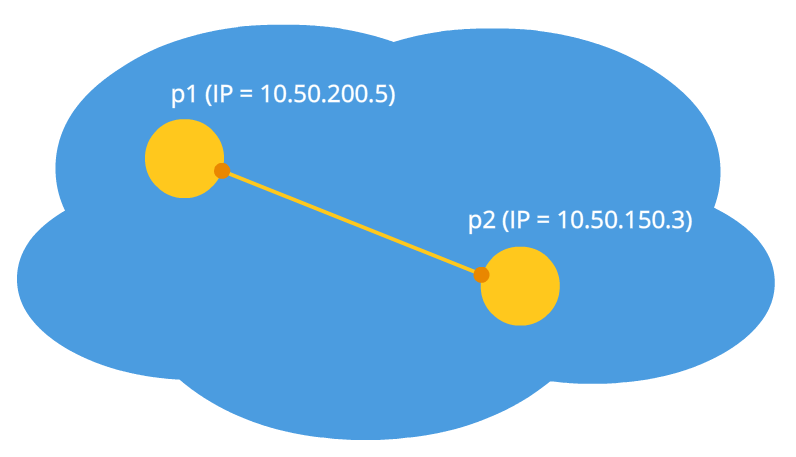 Рисунок 1: Оба узла в одной сети
Рисунок 1: Оба узла в одной сети
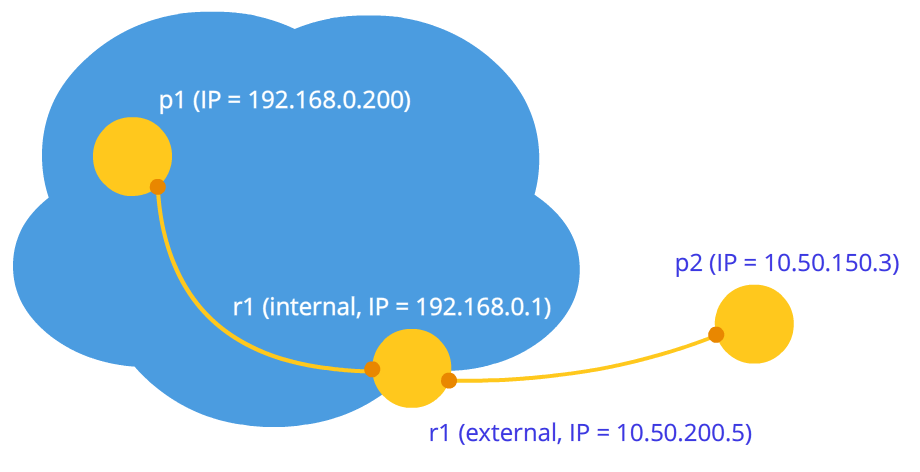 Рисунок 2: Узлы в разных сетях (один в приватной, другой в публичной)
Рисунок 2: Узлы в разных сетях (один в приватной, другой в публичной)
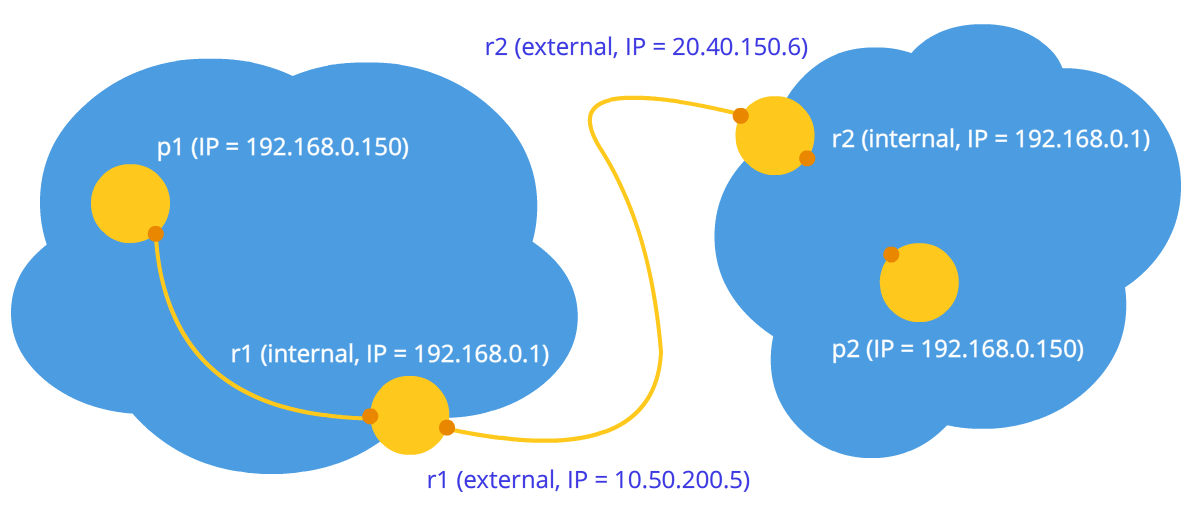 Рисунок 3: Узлы в разных приватных сетях, но с численно
равными адресами
Рисунок 3: Узлы в разных приватных сетях, но с численно
равными адресами
На рисунках выше первая буква в дву-символьных обозначениях означает тип узла (p = peer, r = router). На первом рисунке ситуация благоприятная: узлы в своей сети вполне идентифицируются сетевыми IP адресами и поэтому могут подключаться к друг другу напрямую. На втором рисунке имеем две разные сети, у которых похожие нумерации узлов. Здесь появляются маршрутизаторы (роутеры), у которых есть два сетевых интерфейса – внутри своей сети и вне своей сети. Поэтому у них два IP адреса. Обычные узлы имеют только один интерфейс, через который они могут общаться только в своей сети. Если они передают данные кому-то вне своей сети, то только с помощью NAT внутри маршрутизатора (роутера) и поэтому видимы для других под IP адресом роутера – это их внешний IP адрес. Таким образом, у узла p1 есть внутренний IP = 192.168.0.200 и внешний IP = 10.50.200.5, причем последний адрес будет внешним также и для всех других узлов в его сети1. Похожая ситуация и для узла p2. Поэтому их связь невозможна, если использовать только их внутренние (свои) IP адреса. Можно воспользоваться внешними адресами, то есть адресами роутеров, но, так как у всех узлов в одной приватной сети один и тот же внешний адрес, то это довольно затруднительно. Это проблема решается с помощью механизма NAT
Что же будет, если мы все-таки решим соединить узлы через их внутренние адреса? Данные не выйдут за пределы сети. Для усиления эффекта можно представить ситуацию, изображенную на последнем рисунке – у обоих узлов совпадают внутренние адреса. Если они будут использовать их для коммуникации, то каждый узел будет общаться с самим собой.
WebRTC успешно справляется с такими проблемами, используя протокол ICE, который, правда, требует использования дополнительных серверов (STUN, TURN). Обо всем этом ниже.
Две фазы WebRTC
Чтобы соединить два узла через протокол WebRTC (или просто RTC, если связываются два iPhone‘a) необходимо провести некие предварительные действия для установления соединения. Это первая фаза – установка соединения. Вторая фаза – передача видео-данных.
Сразу стоит сказать, что, хоть технология WebRTC в своей работе использует множество различных способов коммуникации (TCP и UDP) и имеет гибкое переключение между ними, эта технология не имеет протокола для передачи данных о соединении. Не удивительно, ведь подключить два узла p2p не так-то просто. Поэтому необходимо иметь некоторый дополнительный способ передачи данных, никак не связанный с WebRTC. Это может быть сокетная передача, протокол HTTP, это может быть даже протокол SMTP или Почта России2. Этот механизм передачи начальных данных называется сигнальным. Передавать нужно не так много информации. Все данные передаются в виде текста и делятся на два типа – SDP и Ice Candidate. Первый тип используется для установления логического соединения, а второй для физического3. Подробно обо всем этом позже, а пока лишь важно помнить, что WebRTC даст нам некую информацию, которую нужно будет передать другому узлу. Как только мы передадим всю нужную информацию, узлы смогут соединиться и больше наша помощь нужна не будет. Таким образом, сигнальный механизм, который мы должны реализовать отдельно, будет использоваться только при подключении, а при передаче видео-данных использоваться не будет.
Итак, рассмотрим первую фазу – фазу установки соединения. Она состоит из нескольких пунктов. Рассмотрим эту фазу сначала для узла, который инициирует соединение, а потом для ожидающего.
- Инициатор (звонящий – caller):
- Получение локального (своего) медиа потока и установка его для передачи (getUserMediaStream)
- Предложение начать видео-передачу данных (createOffer)
- Получение своего SDP объекта и передача его через сигнальный механизм (SDP)
- Получение своих Ice candidate объектов и передача их через сигнальный механизм (Ice candidate)
- Получение удаленного (чужого) медиа потока и отображение его на экране (onAddStream)
- Ожидающий звонка (callee):
- Получение локального (своего) медиа потока и установка его для передачи (getUserMediaStream)
- Получение предложения начать видео-передачу данных и создание ответа (createAnswer)
- Получение своего SDP объекта и передача его через сигнальный механизм (SDP)
- Получение своих Ice candidate объектов и передача их через сигнальный механизм (Ice candidate)
- Получение удаленного (чужого) медиа потока и отображение его на экране (onAddStream)
Отличие лишь во втором пункте.
Несмотря на кажущуюся запутанность шагов здесь их на самом деле три: отправка своего медиа потока (п.1), установка параметров соединения (пп.2-4), получение чужого медиа потока (п.5). Самый сложный – второй шаг, потому что он состоит из двух частей: установление физического и логического соединения. Первая указывает путь, по которому должны идти пакеты, чтобы дойти от одного узла сети до другого. Вторая указывает параметры видео/аудио – какое использовать качество, какие использовать кодеки.
Мысленно этап createOffer или createAnswer следует соединить с этапами передачи SDP и Ice candidate объектов.
Далее будут рассмотрены некоторые сущности подробнее, а именно – медиапоток (MediaStream), дескриптор сессии (SDP) и кандидаты (Ice candidate).
Основные сущности
Медиа потоки (MediaStream)
Основной сущностью является медиа поток, то есть поток видео и аудио данных, картинка и звук. Медиа потоки бывают двух типов – локальные и удаленные. Локальный получает данные от устройств входа (камера, микрофон), а удаленный по сети. Таким образом у каждого узла есть и локальный, и удаленный поток. В WebRTC для потоков существует интерфейс MediaStream и также существует подинтерфейс LocalMediaStream специально для локального потока. В JavaScript можно столкнуться только с первым, а если использовать libjingle, то можно столкнуться и со вторым.
В WebRTC существует довольно запутанная иерархия внутри потока. Каждый поток может состоять из нескольких медиа дорожек (MediaTrack), которые в свою очередь могут состоять из нескольких медиа каналов (MediaChannel). Да и самих медиа потоков может быть тоже несколько.
Рассмотрим все по порядку. Для этого будем держать в уме некоторый пример. Допустим, что мы хотим передавать не только видео себя, но и видео нашего стола, на котором лежит листок бумаги, на котором мы собираемся что-то писать. Нам понадобится два видео (мы + стол) и одно аудио (мы). Ясно, что мы и стол стоит разделить на разные потоки, потому что эти данные, наверное, слабо зависят друг от друга. Поэтому у нас будет два MediaStream‘a – один для нас и один для стола. Первый будет содержать и видео, и аудио данные, а второй – только видео (Рисунок 4).
 Рисунок 4: Два различных медиа потока. Один для нас, один для нашего стола
Рисунок 4: Два различных медиа потока. Один для нас, один для нашего стола
Сразу ясно, что медиа поток как минимум должен включать в себя возможность содержать данные разных типов — видео и аудио. Это учтено в технологии и поэтому каждый тип данных реализуется через медиа дорожку MediaTrack. У медиа дорожки есть специальное свойство kind, которое и определяет, что перед нами – видео или аудио (Рисунок 5)
 Рисунок 5: Медиа потоки состоят из медиа дорожек
Рисунок 5: Медиа потоки состоят из медиа дорожек
Как будет всё происходить в программе? Мы создадим два медиа потока. Потом создадим две видео дорожки и одну аудио дорожку. Получим доступ к камерам и микрофону. Укажем каждой дорожке какое устройство использовать. Добавим видео и аудио дорожку в первый медиа поток и видео дорожку от другой камеры во второй медиа поток.
Но как мы различим медиа потоки на другом конце соединения? Для этого каждый медиа поток имеет свойство label – метка потока, его название (Рисунок 6). Такое же свойство имеют и медиа дорожки. Хотя на первый взгляд кажется, что видео от звука можно отличить и другими способами.
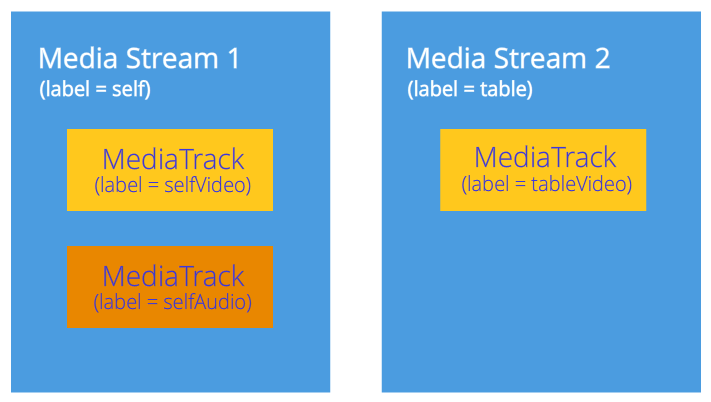 Рисунок 6: Медиа потоки и дорожки идентифицируются метками
Рисунок 6: Медиа потоки и дорожки идентифицируются метками
Так, а если медиа дорожки можно идентифицировать через метку, то зачем нам для нашего примера использовать два медиа потока, вместо одного? Ведь можно передавать один медиа поток, а дорожки использовать в нем разные. Мы дошли до важного свойства медиа потоков – они синхронизируют медиа дорожки. Разные медиа потоки не синхронизируются между собой, но внутри каждого медиа потока все дорожки воспроизводятся одновременно.
Таким образом, если мы хотим, чтобы наши слова, наши эмоции на лице и наш листочек бумаги воспроизводились одновременно, то стоит использовать один медиа поток. Если это не столь важно, то выгодней использовать разные потоки – картинка будет более гладкой4.
Если какую-то дорожку необходимо отключать во время передачи, то можно воспользоваться свойством enabled медиа дорожки.
В конце стоит подумать о стерео звуке. Как известно стерео звук – это два разных звука. И передавать их надо тоже отдельно. Для этого используются каналы MediaChannel. Медиа дорожка звука может иметь много каналов (например, 6, если нужен звук 5+1). Внутри медиа дорожки каналы, разумеется тоже синхронизированы. Для видео обычно используется только один канал, но могут использоваться и несколько, например, для наложения рекламы.
Резюмируя: мы используем медиа поток для передачи видео и аудио данных. Внутри каждого медиа потока данные синхронизированы. Мы можем использовать несколько медиа потоков, если синхронизация нам не нужна. Внутри каждого медиа потока есть медиа дорожки двух видов – для видео и для аудио. Дорожек обычно не больше двух, но может быть и больше, если нужно передавать несколько разных видео (собеседника и его стола). Каждая дорожка может состоять из нескольких каналов, что используется обычно только для стерео звука.
В самой простой ситуации видеочата у нас будет один локальный медиа поток, который будет состоять из двух дорожек – видео дорожки и аудио дорожки, каждая из которых будет состоять из одного основного канала. Видео дорожка отвечает за камеру, аудио дорожка – за микрофон, а медиа поток – это контейнер их обоих.
Дескриптор сессии (SDP)
У разных компьютеров всегда будут разные камеры, микрофоны, видеокарты и прочее оборудование. Существует множество параметров, которыми они обладают. Все это необходимо скоординировать для медиа передачи данных между двумя узлами сети. WebRTC делает это автоматически и создает специальный объект – дескриптор сессии SDP. Передайте этот объект другому узлу, и можно передавать медиа данные. Только связи с другим узлом пока нет5.
Для этого используется любой сигнальный механизм. SDP можно передать хоть через сокеты, хоть человеком (сообщить его другому узлу по телефону), хоть Почтой России. Всё очень просто – Вам дадут уже готовый SDP и его нужно переслать. А при получении на другой стороне – передать в ведомство WebRTC. Дескриптор сессии хранится в виде текста и его можно изменить в своих приложениях, но, как правило, это не нужно. Как пример, при соединении десктоп↔телефон иногда требуется принудительно выбирать нужный аудио кодек.
Обычно при установке соединения необходимо указывать какой-то адрес, например URL. Здесь в этом нет необходимости, так как через сигнальный механизм Вы сами отправите данные по назначению. Чтобы указать WebRTC, что мы хотим установить p2p соединение нужно вызвать функцию createOffer. После вызова этой функции и указания ей специального callback‘a будет создан SDP объект и передан в этот же callback. Все, что от Вас требуется – передать этот объект по сети другому узлу (собеседнику). После этого на другом конце через сигнальный механизм придут данные, а именно этот SDP объект. Этот дескриптор сессии для этого узла чужой и поэтому несет полезную информацию. Получение этого объекта – сигнал к началу соединения. Поэтому Вы должны согласиться на это6 и вызвать функцию createAnswer. Она – полный аналог createOffer. Снова в Ваш callback передадут локальный дескриптор сессии и его нужно будет передать по сигнальному механизму обратно.
Стоит отметить, что вызывать функцию createAnswer можно только после получения чужого SDP объекта. Почему? Потому что локальный SDP объект, который будет генерироваться при вызове createAnswer, должен опираться на удаленный SDP объект. Только в таком случае возможно скоординировать свои настройки видео с настройками собеседника. Также не стоит вызывать createAnswer и createOffer до получения локального медиа потока – им будет нечего писать в SDP объект7.
Так как в WebRTC есть возможность редактирования SDP объекта, то после получения локального дескриптора его нужно установить. Это может показаться немного странным, что нужно передавать WebRTC то, что она сама нам дала, но таков протокол. При получении удаленного дескриптора его нужно тоже установить. Поэтому Вы должны на одном узле установить два дескриптора – свой и чужой (то есть локальный и удаленный).
После такого рукопожатия узлы знают о пожеланиях друг друга. Например, если узел 1 поддерживает кодеки A и B, а узел 2 поддерживает кодеки B и C, то, так как каждый узел знает свой и чужой дескрипторы, оба узла выберут кодек B (Рисунок 7). Логика соединения теперь установлена, и можно передавать медиа потоки, но есть другая проблема – узлы по-прежнему связаны лишь сигнальным механизмом.
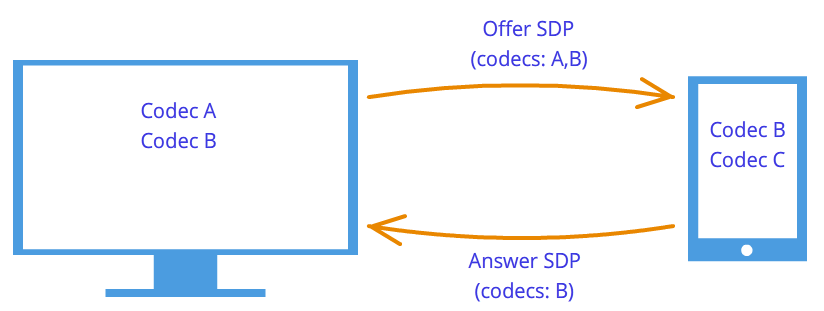
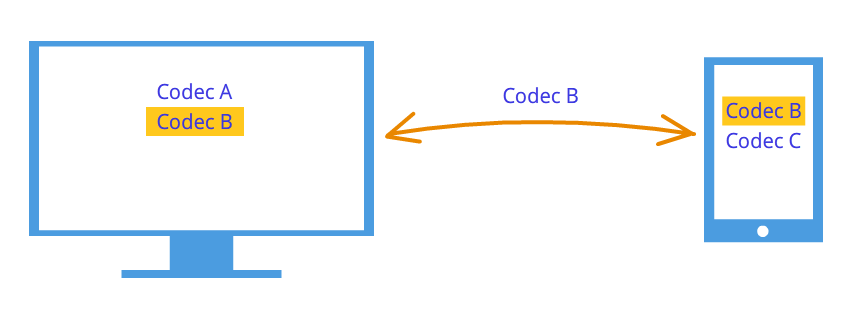 Рисунок 7: Согласование кодеков
Рисунок 7: Согласование кодеков
Кандидаты (Ice candidate)
Технология WebRTC пытается запутать нас своей новой методологией. При установке соединения не указывается адрес того узла, с которым нужно соединиться. Устанавливается сначала логическое соединение, а не физическое, хотя всегда делалось наоборот8. Но это не покажется странным, если не забывать, что мы используем сторонний сигнальный механизм.
Итак, соединение уже установлено (логическое соединение), но пока нет пути, по которому узлы сети могут передавать данные. Здесь не всё так просто, но начнем с простого. Пусть узлы находятся в одной приватной сети. Как мы уже знаем, они могут легко соединяться друг с другом по своим внутренним IP адресам (или быть может, по каким-то другим, если используется не TCP/IP).
Через некоторые callback‘и WebRTC сообщает нам Ice candidate объекты. Они тоже приходят в текстовой форме и также, как с дескрипторами сессии, их нужно просто переслать через сигнальный механизм. Если дескриптор сессии содержал информацию о наших установках на уровне камеры и микрофона, то кандидаты содержат информацию о нашем расположении в сети. Передайте их другому узлу, и тот сможет физически соединиться с нами, а так как у него уже есть и дескриптор сессии, то и логически сможет соединиться и данные «потекут». Если он не забудет отправить нам и свой объект кандидата, то есть информацию о том, где находится он сам в сети, то и мы сможем с ним соединиться. Заметим здесь еще одно отличие от классического клиент-серверного взаимодействия. Общение с HTTP сервером происходит по схеме запрос-ответ, клиент отправляет данные на сервер, тот обрабатывает их и шлет по адресу, указанному в пакете запроса. В WebRTC необходимо знать два адреса и соединять их с двух сторон.
Различие от дескрипторов сессии состоит в том, что устанавливать нужно только удаленных кандидатов. Редактирование здесь запрещено и не может принести никакой пользы. В некоторых реализациях WebRTC кандидатов необходимо устанавливать только после установки дескрипторов сессии9.
А почему дескриптор сессии был один, а кандидатов может быть много? Потому что расположение в сети может определяться не только своим внутренним IP адресом, но также и внешним адресом маршрутизатора, и не обязательно одного, а также адресами TURN серверов. Остаток параграфа будет посвящен подробному рассмотрению кандидатов и тому, как соединять узлы из разных приватных сетей.
Итак, два узла находятся в одной сети (Рисунок 8). Как их идентифицировать? С помощью IP адресов. Больше никак. Правда, еще можно использовать разные транспорты (TCP и UDP) и разные порты. Это и есть та информация, которая содержится в объекте кандидата – IP, PORT, TRANSPORT и какая-то другая. Пусть, для примера, используется UDP транспорт и 531 порт.
Рисунок 8: Два узла находятся в одной сети
Тогда, если мы находимся в узле p1, то WebRTC передаст нам такой объект кандидата — [10.50.200.5, 531, udp]. Здесь приводится не точный формат, а лишь схема. Если мы в узле p2, то кандидат таков – [10.50.150.3, 531, udp]. Через сигнальный механизм p1 получит кандидата p2 (то есть расположение узла p2, а именно его IP и PORT). После чего p1 может соединиться с p2 напрямую. Более правильно, p1 будет посылать данные на адрес 10.50.150.3:531 в надежде, что они дойдут до p2. Не важно, принадлежит ли этот адрес узлу p2 или какому-то посреднику. Важно лишь то, что через этот адрес данные будут посылаться и могут достигнуть p2.
Пока узлы в одной сети – все просто и легко – каждый узел имеет только один объект кандидата (всегда имеется в виду свой, то есть свое расположение в сети). Но кандидатов станет гораздо больше, когда узлы будут находится в разных сетях.
Перейдем к более сложному случаю. Один узел будет находиться за роутером (точнее, за NAT), а второй узел будет находиться в одной сети с этим роутером (например, в интернете) (Рисунок 9).
Рисунок 9: Один узел за NAT, другой нет
Этот случай имеет частное решение проблемы, которое мы сейчас и рассмотрим. Домашний роутер обычно содержит таблицу NAT. Это специальных механизм, разработанный для того, чтобы узлы внутри приватной сети роутера смогли обращаться, например, к веб-сайтам.
Предположим, что веб-сервер соединен с интернетом напрямую, то есть имеет публичным IP* адрес. Пусть это будет узел p2. Узел p1 (веб-клиент) шлет запрос на адрес 10.50.200.10. Сначала данные попадают на роутер r1, а точнее на его внутренний интерфейс 192.168.0.1. После чего, роутер запоминает адрес источника (адрес p1) и заносит его в специальную таблицу NAT, затем изменяет адрес источника на свой(p1 → r1). Далее, по своему внешнему интерфейсу роутер пересылает данные непосредственно на веб‑сервер p2. Веб-сервер обрабатывает данные, генерирует ответ и отправляет обратно. Отправляет роутеру r1, так как именно он стоит в обратном адресе (роутер подменил адрес на свой). Роутер получает данные, смотрит в таблицу NAT и пересылает данные узлу p1. Роутер выступает здесь как посредник.
А что если несколько узлов из внутренней сети одновременно обращаются к внешней сети? Как роутер поймет кому отправлять ответ обратно? Эта проблема решается с помощью портов. Когда роутер подменяет адрес узла на свой, он также подменяет и порт. Если два узла обращаются к интернету, то роутер подменяет их порты источников на разные. Тогда, когда пакет от веб‑сервера придет обратно к роутеру, то роутер поймет по порту, кому назначен данный пакет. Пример ниже.
Вернемся к технологии WebRTC, а точнее, к ее части, которая использует ICE протокол (отсюда и Ice кандидаты). Узел p2 имеет одного кандидата (свое расположение в сети – 10.50.200.10), а узел p1, который находится за роутером с NAT, будет иметь двух кандидатов – локального (192.168.0.200) и кандидата роутера (10.50.200.5). Первый не пригодится, но он, тем не менее, генерируется, так как WebRTC еще ничего не знает об удаленном узле – он может находиться в той же сети, а может и нет. Второй кандидат пригодится, и, как мы уже знаем, важную роль будет играть порт (чтобы пройти через NAT).
Запись в таблице NAT генерируется только когда данные выходят из внутренней сети. Поэтому узел p1 должен первым передать данные и только после этого данные узла p2 смогут добраться до узла p1.
На практике оба узла будут находиться за NAT. Чтобы создать запись в таблице NAT каждого роутера, узлы должны что-то отправить удаленному узлу, но на этот раз ни первый не может добраться до второго, ни наоборот. Это связано с тем, что узлы не знают своих внешних IP адресов, а отправлять данные на внутренние адреса бессмысленно.
Однако, если внешние адреса известны, то соединение будет легко установлено. Если первый узел отошлет данные на роутер второго узла, то роутер их проигнорирует, так как его таблица NAT пока пуста. Однако в роутере первого узла в таблице NAT появилась нужна запись. Если теперь второй узел отправит данные на роутер первого узла, то роутер их успешно передаст первому узлу. Теперь и таблица NAT второго роутера имеет нужны данные.
Проблема в том, что, чтобы узнать своей внешний IP адрес, нужен узел находящийся в общей сети. Для решения такой проблемы используются дополнительные сервера, которые подключены к интернету напрямую. С их помощью также создаются заветные записи в таблице NAT.
STUN и TURN сервера
При инициализации WebRTC необходимо указать доступные STUN и TURN сервера, которые мы в дальнейшем будем называть ICE серверами. Если сервера не будут указаны, то соединиться смогут только узлы в одной сети (подключенные к ней без NAT). Сразу стоит отметить, что для 3g-сетей обязательно использование TURN серверов.
STUN сервер – это просто сервер в интернете, который возвращает обратный адрес, то есть адрес узла отправителя. Узел, находящий за роутером, обращается к STUN серверу, чтобы пройти через NAT. Пакет, пришедший к STUN серверу, содержит адрес источника – адрес роутера, то есть внешний адрес нашего узла. Этот адрес STUN сервер и отправляет обратно. Таким образом, узел получает свой внешний IP адрес и порт, через который он доступен из сети. Далее, WebRTC с помощью этого адреса создает дополнительного кандидата (внешний адрес роутера и порт). Теперь в таблице NAT роутера есть запись, которая пропускает к нашему узлу пакеты, отправленные на роутер по нужному порту.
Рассмотрим этот процесс на примере.
Пример (работа STUN сервера)
STUN сервер будем обозначать через s1. Роутер, как и раньше, через r1, а узел – через p1. Также необходимо будет следить за таблицей NAT – ее обозначим как r1_nat. Причем в этой таблице обычно содержится много записей от разный узлов подсети – они приводиться не будут.
Итак, в начале имеем пустую таблицу r1_nat.
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
Таблица 1: Пустая таблица NAT
В таблице 4 столбца. Она задает отображение первых двух столбцов на два последних, то есть каждой паре (IP, PORT), которая адресует узел во внутренней приватной сети, сопоставляется пара (IP, PORT) из внешней публичной сети.
Узел p1 отправляет пакет узлу s1 (STUN серверу). Ниже в таблице указаны четыре интересующие нас поля в заголовке транспортного пакета (TCP или UDP) – IP и PORT источника и приемника. Пусть адреса будут такими:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 12.62.100.200 | 6000 |
Таблица 2: Заголовок пакета
Узел p1 отправляет этот пакет роутеру r1 (не важно каким образом, в разных подсетях могут быть использованы разные технологии). Роутеру необходимо сделать подмену адреса источника Src IP, так как указанный в пакете адрес заведомо не подойдет для внешней подсети, более того, адреса из такого диапазона зарезервированы, и ни один адрес в интернете не имеет такого адреса. Роутер делает подмену в пакете и создает новую запись в своей таблице r1_nat. Для этого ему нужно придумать номер порта. Напомним, что, так как несколько узлов внутри подсети могут обращаться к внешней сети, то в таблице NAT должна храниться дополнительная информация, чтобы роутер смог определить, кому из этих нескольких узлов предназначается обратный пакет от сервера. Пусть роутер придумал порт 888.
Измененный заголовок пакета:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 10.50.200.5 | 888 | 12.62.100.200 | 6000 |
Таблица 3: Роутер подменил адрес источника на свой
Где 10.50.200.5 – это внешний адрес роутера.
Таблица r1_nat:
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
Таблица 4: Таблица NAT пополнилась новой записью
Здесь IP адрес и порт для подсети абсолютно такие же, как у исходного пакета. В самом деле, при обратной передаче мы должны иметь способ полностью их восстановить. IP адрес для внешней сети – это адрес роутера, а порт изменился на придуманный роутером.
Настоящий порт, на который узел p1 принимает подключение – это, разумеется, 35777, но сервер шлет данные на фиктивный порт 888, который будет изменен роутером на настоящий 35777.
Итак, роутер подменил адрес и порт источника в заголовке пакета и добавил запись в таблицу NAT. Теперь пакет отправляется по сети серверу, то есть узлу s1. На входе, s1 имеет такой пакет:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 10.50.200.5 | 888 | 12.62.100.200 | 6000 |
Таблица 5: STUN сервер получил пакет
Итого, STUN сервер знает, что ему пришел пакет от адреса 10.50.200.5:888. Теперь этот адрес сервер отправляет обратно. Здесь стоит остановиться и еще раз посмотреть, что мы только что рассматривали. Таблицы, приведенные выше – это кусочек из заголовка пакета, вовсе не из его содержимого. О содержимом мы не говорили, так как это не столь важно – оно как-то описывается в протоколе STUN. Теперь же мы будем рассматривать помимо заголовка еще и содержимое. Оно будет простым и содержать адрес роутера – 10.50.200.5:888, хотя взяли мы его из заголовка пакета. Такое делается не часто, обычно протоколам не важна информация об адресах узлов, важно лишь, чтобы пакеты доставлялись по назначению. Здесь же мы рассматриваем протокол, который устанавливает путь между двумя узлами.
Итак, теперь у нас появляется второй пакет, который идет в обратном направлении:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 10.50.200.5 | 888 |
Таблица 6: STUN сервер отправляет пакет с таким заголовком
Заголовок изменился очень просто – источник и приемник поменялись местами, что логично, так как направление пакета теперь другое.
| Content |
|---|
| 10.50.200.5:888 |
Таблица 7: STUN сервер отправляет пакет с таким содержимым
Это уже содержание пакета. На самом деле, оно может содержать много информации, но здесь указано лишь то, что важно для понимания работы STUN сервера.
Далее, пакет путешествует по сети, пока не окажется на внешнем интерфейсе роутера r1. Роутер понимает, что пакет предназначен не ему. Как он это понимает? Это можно узнать только по порту. Порт 888 он не использует для своих личных целей, а использует для механизма NAT. Поэтому в эту таблицу роутер и смотрит. Смотрит на столбец External PORT и ищет строку, которая совпадет с Dest PORT из пришедшего пакета, то есть 888.
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
Таблица 8: Таблица NAT
Нам повезло, такая строчка существует. Если бы не повезло, то пакет бы просто отбросился. Теперь нужно понять, кому из узлов подсети надо отправлять этот пакет. Не стоит торопиться, давайте снова вспомним о важности портов в этом механизме. Одновременно два узла в подсети могли бы отправлять запросы во внешнюю сеть. Тогда, если для первого узла роутер придумал порт 888, то для второго он бы придумал порт 889. Предположим, что так и случилось, то есть таблица r1_nat выглядит так:
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
| 192.168.0.173 | 35777 | 10.50.200.5 | 889 |
Таблица 9: Таблица NAT
По порту 888 понятно, что нужный внутренний адрес это 192.168.0.200:35777. Роутер заменяет адрес приемника с
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 10.50.200.5 | 888 |
Таблица 10: Роутер подменяет адрес приемника
На
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 192.168.0.200 | 35777 |
Таблица 11: Роутер подменил адрес приемника
Пакет успешно приходит к узлу p1 и, посмотрев на содержимое пакета, узел узнает о своем внешнем IP адресе, то есть об адресе роутера во внешней сети. Также он знает и порт, который роутер пропускает через NAT.
Что же дальше? Какая от этого всего польза? Польза – это запись в таблице r1_nat. Если теперь кто угодно будет отправлять на роутер r1 пакет с портом 888, то роутер перенаправит этот пакет узлу p1. Таким образом, создался небольшой узкий проход к спрятанному узлу p1.
Из примера выше можно получить некоторое представление о работе NAT и сути STUN сервера. Вообще, механизм ICE и STUN/TURN сервера как раз и направлены на преодоления ограничений NAT.
Между узлом и сервером может стоять не один роутер, а несколько. В таком случае узел получит адрес того роутера, который является первым выходящим в ту же сеть, что и сервер. Иными словами, получим адрес роутера, подключенного к STUN серверу. Для p2p коммуникации это как раз то, что нам нужно, если не забыть тот факт, что в каждом роутере добавится необходимая нам строчка в таблицу NAT. Поэтому обратный путь будет вновь так же гладок.
TURN сервер – это улучшенный STUN сервер. Отсюда сразу следует извлечь, что любой TURN сервер может работать и как STUN сервер. Однако, есть и преимущества. Если p2p коммуникация невозможна (как например, в 3g сетях), то сервер переходит в режим ретранслятора (relay), то есть работает как посредник. Разумеется, ни о каком p2p тогда речь не идет, но за рамками механизма ICE узлы думают, что общаются напрямую.
В каких случаях необходим TURN сервер? Почему не хватает STUN сервера? Дело в том, что существует несколько разновидностей NAT. Они одинаково подменяют IP адрес и порт, однако в некоторые из них встроена дополнительная защита от “фальсификации”. Например, в симметричной таблице NAT сохраняются еще 2 параметра - IP и порт удаленного узла. Пакет из внешней сети проходит через NAT во внутреннюю сеть только в том случае, если адрес и порт источника совпадают с записанными в таблице. Поэтому фокус со STUN сервером не удается - таблица NAT хранит адрес и порт STUN сервера и, когда роутер получает пакет от WebRTC собеседника, он его отбрасывает, так как он “фальсифицирован”. Он пришел не от STUN сервера.
Таким образом TURN сервер нужен в том случае, когда оба собеседника находятся за симметричным NAT (каждый за своим).
Краткая сводка
Здесь приведены некоторые утверждения о сущностях WebRTC, которые необходимо всегда держать в голове. Подробно они описаны выше. Если какие-то из утверждений Вам покажутся не до конца ясными, перечитайте соответствующие параграфы.
- Медиа поток
- Видео и аудио данные упаковываются в медиа потоки
- Медиа потоки синхронизируют медиа дорожки, из которых состоят
- Различные медиа потоки не синхронизированы между собой
- Медиа потоки могут быть локальными и удаленными, к локальному обычно подключена камера и микрофон, удаленные получают данные из сети в кодированном виде
- Медиа дорожки бывают двух типов – для видео и для аудио
- Медиа дорожки имеют возможность включения/выключения
- Медиа дорожки состоят из медиа каналов
- Медиа дорожки синхронизируют медиа каналы, из которых состоят
- Медиа потоки и медиа дорожки имеют метки, по которым их можно различать
- Дескриптор сессии
- Дескриптор сессии используется для логического соединения двух узлов сети
- Дескриптор сессии хранит информацию о доступных способах кодирования видео и аудио данных
- WebRTC использует внешний сигнальный механизм – задача пересылки дескрипторов сессии (sdp) ложится на приложение
- Механизм логического соединения состоит из двух этапов – предложения (offer) и ответа (answer)
- Генерация дескриптора сессии невозможна без использования локального медиа потока в случае предложения (offer) и невозможна без использования удаленного дескриптора сессии в случае ответа (answer)
- Полученный дескриптор надо отдать реализации WebRTC, причем неважно, получен ли этот дескриптор удаленно или же локально от той же реализации WebRTC
- Имеется возможность небольшой правки дескриптора сессии
- Кандидаты
- Кандидат (Ice candidate) – это адрес узла в сети
- Адрес узла может быть своим, а может быть адресом роутера или TURN сервера
- Кандидатов всегда много
- Кандидат состоит из IP адреса, порта и типа транспорта (TCP или UDP)
- Кандидаты используются для установления физического соединения двух узлов в сети
- Кандидатов также нужно пересылать через сигнальный механизм
- Кандидатов также нужно передавать реализации WebRTC, однако только удаленных
- В некоторых реализациях WebRTC кандидатов можно передавать только после установки дескриптора сессии
- STUN/TURN/ICE/NAT
- NAT – механизм обеспечения доступа к внешней сети
- Домашние роутеры поддерживают специальную таблицу NAT
- Роутер подменяет адреса в пакетах – адрес источника на свой, в случае, если пакет идет во внешнюю сеть, и адрес приемника на адрес узла во внутренней сети, если пакет пришел из внешней сети
- Для обеспечения многоканального доступа к внешней сети NAT использует порты
- ICE – механизм обхода NAT
- STUN и TURN сервера – сервера-помошники для обхода NAT
- STUN сервер позволяет создавать необходимые записи в таблице NAT, а также возвращает внешний адрес узла
- TURN сервер обобщает STUN механизм и делает его работающим всегда
- В наихудших случаях TURN сервер используется как посредник (relay), то есть p2p превращается в клиент-сервер-клиентную связь.
Сноски:
-
Так как у всех узлов в этой сети один и тот же роутер. ↩
-
Этот шуточный пример всегда полезно держать в голове, чтобы различать коммуникацию в технологии WebRTC от сигнальной коммуникации ↩
-
Очень упрощенно. На деле SDP - это единственные данные которые передаются, а кандидаты это его часть. ↩
-
На синхронизацию всегда тратится дополнительное время. ↩
-
Во времена Vanilla Ice кандидаты передавались внутри SDP, поэтому связь уже есть. ↩
-
Можно только согласиться, отказаться нельзя. В случае отказа нужно просто игнорировать запрос на соединение. ↩
-
Тем не менее, в некоторых реализациях это возможно. Но в том лишь случае, если есть доступ к настройкам видео. Браузеры не могут обращаться к камере до получения медиа потока. ↩
-
Например, при соединении ftp-клиента с ftp-сервером сначала устанавливается TCP-соединение (для протокола прикладного уровня протокол транспортного уровня можно считать физическим), а только потом передаются данные по протоколу FTP (то есть логика протокола). ↩
-
Такова реализация libjingle и некоторых браузеров. Это так, потому что кандидаты являются частью SDP объекта и записываются в него. ↩